
By Borbála Dömötörfy and Alexis Brunelle
The 21st century is an age of information overload: we all struggle with constant “infoxication” in almost every area of our lives. This is especially noticeable when we browse online. Computational power used to process information has been subject to exponential growth during the last decades, and the human brain’s evolution just cannot keep up with this process. This might create information anxiety, which was described by Wurman as early as in 1989: the phenomenon already existed before the world wide web, but the exponential growth of the amount of information, the stress caused by constant availability, information overload and the lack of stable reference points makes it even harder for people to cope with.
Unlike modern computers, the human brain doesn’t have unlimited processing power, and evolution cannot keep up with the speed of technological development, although the digital age has already caused certain changes in the functioning of our memory.
Selecting and collecting relevant information is therefore crucial for optimal choice, which makes technological filtering functions necessary, even though they don’t come without a risk.

We all know the memes and jokes about information ‘cemeteries’ on Google’s second page, but the “filtering function” in the sense we refer to is not limited to search engines. All information ever collected and made available to the public, as well as the way it is presented, are already “filtered”, either consciously, or unconsciously.
Data Problems
First of all, research has pointed out: data itself is not neutral. Information and Data Science are disciplines that should seek to understand data not as neutral or objective, but rather as the products of complex social processes. Concerning potential issues linked to information itself, let’s focus on structured datasets for the sake of simplicity.
As the authors of the book Data Feminism point out, there is a risk “not only that datasets are biased or unrepresentative, but that they never get collected at all.” If data is not collected, or if data collection or recording contains biases (in that it is collected in a way that does not represent correctly the population or universe to which the information refers), it will certainly lead to biased inference or unexpected algorithmic outcomes.
These biases during the process of data gathering are transferred directly to algorithms and apps. Melanie Mitchell described with great clarity how machine learning based on pictures or words used on the Internet incorporates and reinforces societal biases. This is not tomorrow’s problem. For example, artists coming from smaller countries or female artists have already been suffering the (financial) consequences of the fact that recommendation systems and other autonomous systems are learning from historically biased or patchy data.
Presentation Problems
Concerning the presentation of data/information, most of us are familiar with the fact that the way data visualization is organized can also be misleading. The bar graphs below provide a bad and a good example, respectively.
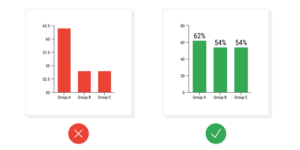
Misleading data visualization however is not the only relevant case for us: all websites have an information architecture, and content is presented in a given way. Whether this presentation is carefully designed on the basis of scientific results, or simply ad hoc, it is the result of a series of decisions – generally very conscious ones – about which information to present, and in which way to present it to the users.
In any case, one thing is certain: relevant information it is not presented in a neutral way because there is no neutral, objective way to present data.
This is illustrated by the “framing effect” in psychology and decision science. The framing effect suggests that “our decisions are influenced by the way information is presented. Just the way of the presentation can make information more or less attractive depending on what features are highlighted.” The order in which the information is presented also matters, as evident in primacy and recency effects, as well as nudges and their evil counterpart, sludges.
If information design is applied, it is important to know whose interest is served by the information design layout. It may serve the users’ own interest (e.g. fitness tracker reminding user to do training), the seller’s interest (e.g. increasing sales) or the benefit of others (e.g. providing a donation to a charity organization). There can also be altruistic motives (e.g. fighting climate change). In that respect, another important question is who decides what information is presented (i.e. can I set my fitness tracker when and how to remind me to do the training?).
Dark Patterns
This leads us to dark patterns – the sludges of the digital world. Harry Brignull defines them as “[a] user interface that has been carefully crafted to trick users into doing things. They are not mistakes, they are carefully crafted with a solid understanding of human psychology, and they do not have the user’s interests in mind.”
Dany Sapio lists the following 10 examples of dark patterns:
- Bait and Switch
- Disguised Ad
- Misdirection
- Friend Spam
- Hidden Costs
- Trick Question
- Confirmshaming
- Roach Motel
- FOMO (Fear of Missing Out)
- Sneak into Basket
Just to give some examples: the picture above is an obvious case of confirmshaming. Disguised ads appear as other kinds of content or navigation, in order to get you to click on them. Misdirection purposefully focuses your attention on one thing in order to distract your attention from another. Trick questions are purposefully crafted to confuse, by using different language artifices, such as intricate wording and double negatives in order to nudge the user into taking the desired action.

Dark patterns in themselves present a serious risk for the decision process of users and create challenges not only from behavioral science, but also from ethical and legal (especially consumer protection, data privacy, and competition law) point of view. Dark patterns, however, have reached unprecedented effectiveness by becoming powered by machine learning. Traditionally, they have been designed by humans, but recently the machine learning powered versions started to enjoy an increasing popularity. The risks associated with these two different types are not the same.
Kinnaird summarizes the difference between UX designer and machine learning powered dark patterns as follows:

This also highlights the unprecedented level of risk presented by the machine learning powered version for human behavior. Without underestimating the “UX designer powered” version, which also has serious distorting effect on the users’ decision-making process, we can see that machine learning powered dark pattern is a completely new phenomenon. Not only volume, velocity and variety are different, but the effects associated with this type differ from those of the UX designer powered counterpart: it doesn’t just trick us to do something, but alters human behavior, and does so in a durable, undetectable and indefensible way.
Professional Ethics and Legislative Attempts Targeting Dark Patterns
For the average consumer, defending themselves from UX designer powered dark patterns has already been considered challenging or impossible. Professional ethics (e.g. UX design ethics, behavioral science ethics, AI ethics) have been focusing on dark patterns for a while.
Recently, several legislative attempts were initiated to address dark patterns (e.g. the recent guidance notice of the UCP Directive which aims to clarify consumers’ rights and simplify cross-border trade within the EU, or the “dark pattern infringement” in article 25 of the recently published Digital Service Act). National and European legislators are actively working on the creation of an effective and efficient regulatory system which would make national economies and the Single Digital Market fit for the digital age while keeping consumers safe and their rights protected. However, legislation – especially at the supranational level – and law enforcement are slow processes, while the tech industry is probably the fastest-changing ecosystem ever. What is ruled on today is often yesterday’s problem. This is especially true in the case of machine-learning-powered practices. Furthermore, public authorities enforcing the law have limited capacity and sometimes lack special expertise in that field.
In our view – and referring to the chapters of Between Brains dealing with ethics – self-regulation and professional ethics, including applied behavioral science ethics will have a major role in making AI trustworthy and digital spaces the safest possible for consumers.
An interesting example of such cooperation between professional actors and law enforcement can for example be found in the French institution of the “Commission des clauses abusives”. In the context of the consumer law enforcement, this commission, composed of judges, civil servants, professionals and consumer association representatives, issues non-binding opinions on certain contractual clauses and maintains a rich database of opinions and case law.
This could constitute a usable reference point for industry actors that wish to develop a coherent compliance policy regarding potential dark patterns in algorithms and apps.
Conclusion
Compliance mechanisms, whether they are based on legally binding provisions or on professional ethics, will not solve alone the crucial issue of biases due to the fact that some data is never gathered or never analyzed, simply because it does not constitute the focus of mainstream economic actors.
To avoid blind spots and inequality of treatment linked to “unborn data”, active public policy regarding digital diversity is probably warranted. European public policy should therefore encourage the gathering of data on human dimensions that are not strictly economic, while providing a coherent framework guaranteeing a safe and transparent use of such sensitive information. It should also give access to computational power to a wider range of actors, including projects coming from other fields than computer and data science.
Such combination of large encompassing legal rules, professional ethics and targeted public investment could then provide a faster, industry-specific, voluntary, and tailor-made environment to ensure legal and ethical compliance, and could hopefully contribute to the creation of a safer, more human and trustworthy digital age.
We are deeply grateful to Judit Firniksz, MSc., LL.M., and Daniel Antal, CFA for all the interesting and insightful conversations which provided inspiration for this article, and for their comments. All views, thoughts and opinions belong solely to the authors and do not necessarily reflect those of their respective employers.

